
Projects
Explore my ML and Data Science Projects
MET Art Display Predictor
Personal project modeling artwork exhibition likelihood - using data from the Metropolitan Museum of Art
Gradient Boosting
MLOps
Data Analysis
Objective
While visiting art galleries, I've always wondered what makes a piece of art valuable. Here I present a full analysis of the Metropolitan Museum of Art Open Access dataset and a Gradient Boosting model that scores artworks and learns patterns behind which pieces are selected for display. This is a data-driven perspective on the inherently subjective nature of art.
Key Responsibilities & Actions
- Built an end-to-end pipeline: ingest MET Open Access data, clean it, and create a combined text field plus curated metadata features.
- Performed exploratory data analysis to understand label imbalance, department/category patterns, and to select/shape features used for modeling.
- Generated text embeddings with a pre-trained SentenceTransformer (all-MiniLM-L6-v2) and trained a CatBoost classifier that mixes embeddings with categorical and numeric inputs (using CatBoost's native categorical handling and class balancing).
- Ran hyperparameter optimization.
- Validated the model with evaluation and error analysis, and measured input influence via permutation tests and text ablations (dropping specific text fields and re-embedding).
- Deployed the trained model as a containerized FastAPI service on Google Cloud Run. It returns the probability and label. You can test it yourself below! Keep in mind the first request with take a minute to start the service.
- Ensured continuous updates on the Dataset analysis dashboard as an indication of the relevance of the model and need of retraining.
Key Results
- Model performance is strong (see the dashboard), with results supported by error analysis and column-impact tests.
- Department was the strongest non-text driver; shuffling it dropped PR-AUC by ~0.34 on a 1k test sample.
- The text embeddings contributed most of the predictive signal overall, with dates and categories adding smaller but meaningful gains.
Try the Model
Dataset Analysis
Loading...
Total Artworks
Loading...
On Display
Loading...
In Storage
Class Distribution
On View
Not On View
Loading...
--%
New and updated pieces since last retrain
Last updated: Loading...
Model Performance Dashboard
Loading...
Master's Thesis - Modality fusion in enzyme interaction prediction
Modality-fusion strategies for a transformer predicting enzyme-substrate interactions
Bioinformatics
Deep Learning
Modality Fusion
Objective
Improved state-of-the-art prediction of protein-small molecule interactions by incorporating 3D protein structural data into a pre-trained multimodal transformer to enhance model generalizability and robustness.
Key Responsibilities & Actions
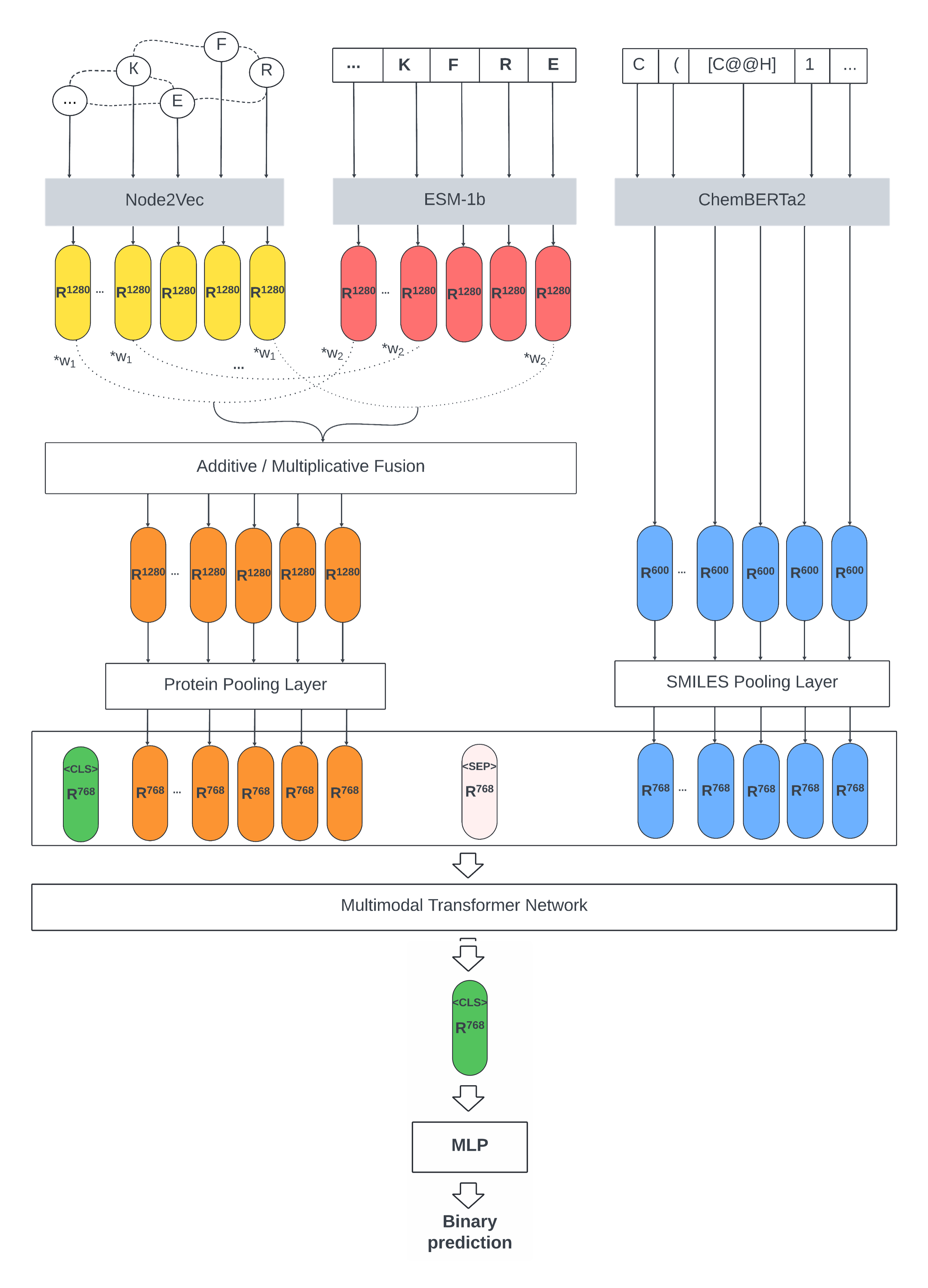
- Constructed a novel dataset of ~185,000 data points by mapping protein sequences to 3D structures from AlphaFold using the Graphein library.
- Represented protein structures as graphs and generated node embeddings using the Node2Vec algorithm.
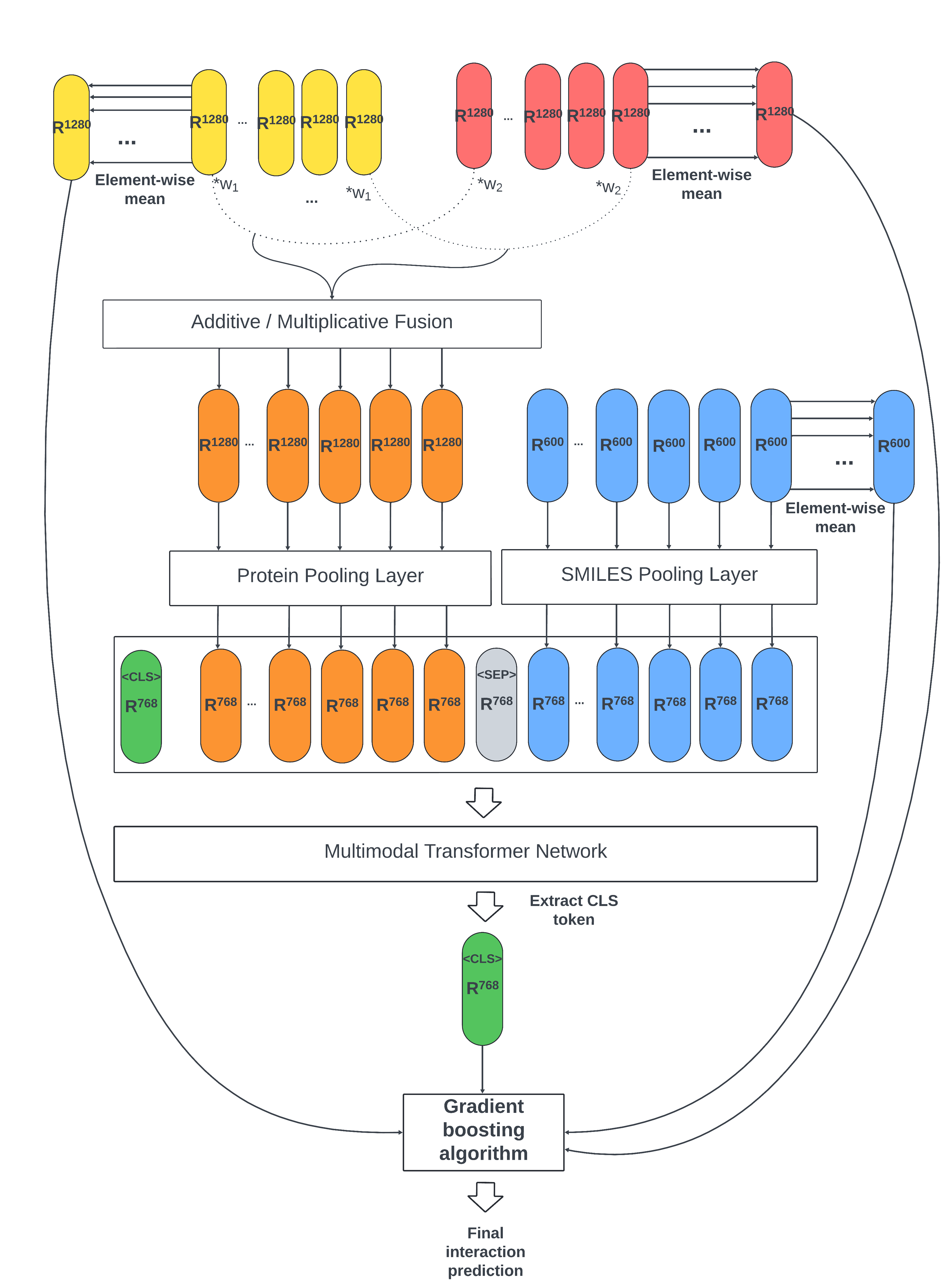
- Designed & implemented novel modality fusion techniques (additive & multiplicative) to merge protein sequence and structural embeddings before feeding them into a pre-trained transformer, avoiding costly retraining from scratch.
- Trained and evaluated model performance end-to-end, including a gradient boosting (XGBoost) ensemble step, across various data split scenarios (random, cold protein, cold SMILES).
Key Results
- Validated that the model maintains high performance (~97% accuracy) on standard random splits.
- Demonstrated improved generalization, achieving a ~1% accuracy increase on challenging "cold start" splits with unseen small molecules—the primary failure mode of the original model.
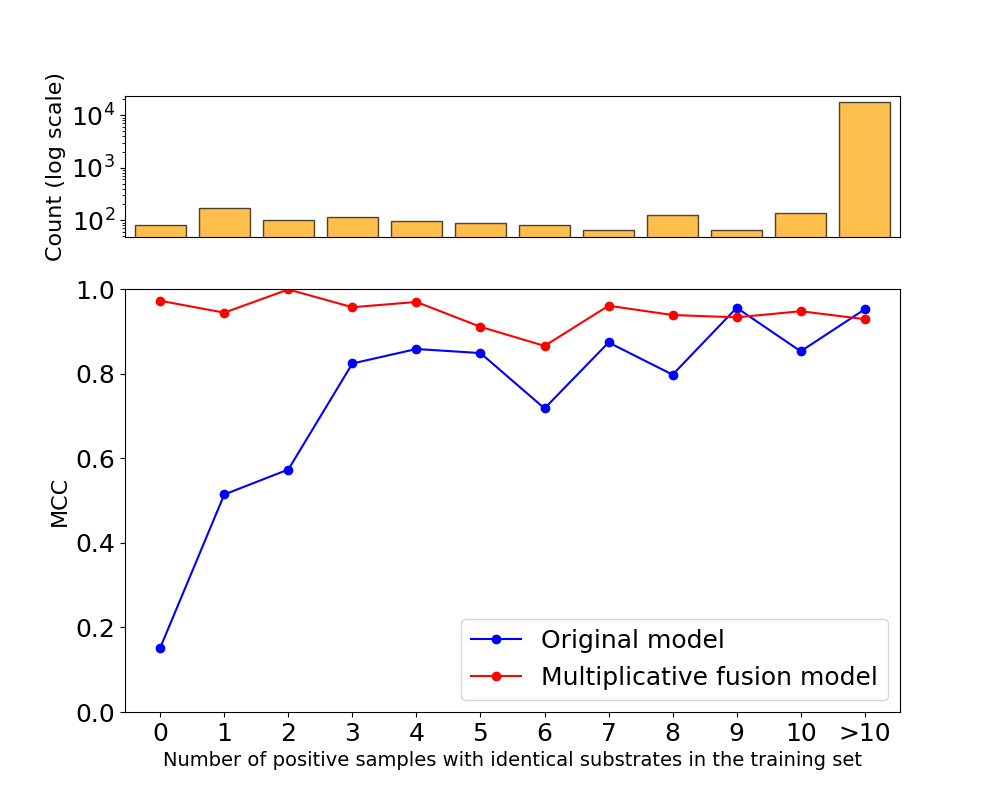
- Showcased significantly better performance (via MCC score) for rare, underrepresented substrates, highlighting the model's potential for novel discovery.
Master's Thesis
Click to view PDF
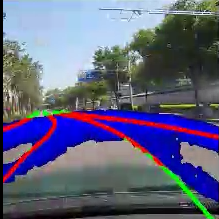
Tranformer-based Lane Detection
Transformer-based lane detection that leverages spatiotemporal information from sequential video frames to robustly dynamic road conditions
Computer Vision
Deep Learning
Transformers
Objective
Improve robustness of lane detection through leveraging spatiotemporal context from video sequences by using Transormer-based architecture.
Personal Responsibilities & Actions
- Curated and preprocessed large-scale driving datasets (CULane: 55h / 133k frames, TuSimple), converting lane point annotations into segmentation masks.
- Designed and applied a data augmentation pipeline (random flips, rotations ±30°, crops, and normalization) to improve robustness to camera pose changes, occlusions, and viewpoint shifts.
- Built a transformer-based segmentation pipeline that leverages temporal information across video frames to improve lane detection consistency.
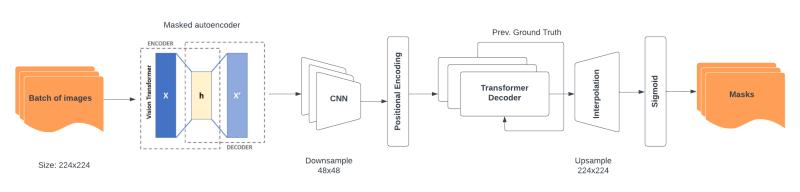
- Evaluated and replaced a ResNet34 backbone with a self-supervised MAE-ViT, validating superior lane-specific feature extraction via custom image-reconstruction experiments.
Key Results
- Demonstrated MAE-ViT's advantage over CNN backbones for capturing long, thin, and partially occluded lane structures.
- Showed that temporal modeling with transformers stabilizes training and improves qualitative lane predictions under challenging conditions.
- Delivered a validated proof-of-concept under strict hardware constraints.



Project Report
Click to view PDF
Lindel
Reproducing, Evaluating and Interpreting the Lindel Model for CRISPR-Cas9 Repair Outcome Prediction
Bioinformatics
Machine Learning
Model Interpretation
Objective
In a collaborative academic project, our team reproduced and validated key findings from Chen et al.'s seminal work on predicting CRISPR-Cas9 DNA repair outcomes. My individual contribution centered on interpreting the model's internal logic to assess whether the logistic regression model used to predict the insertion–deletion (indel) ratio learns the same sequence context importance as reported in the original paper.
Key Responsibilities & Actions
- Successfully replicated the core functionality of the Lindel machine learning model, confirming both its superiority over a baseline model and the high reproducibility of mutational outcomes across experiments.
- Performed learned weights analysis of the neural network to understand the model's decision-making process.
- Applied SHAP (SHapley Additive exPlanations) to quantify feature importance and identify which sequence elements drive predictions.
- Conducted Multiple Correspondence Analysis (MCA) to examine relationships in categorical sequence data and validate claimed dinucleotide patterns.
- Critically evaluated the authors' claims regarding sequence context importance through complementary interpretability techniques.
Key Results
- Confirmed the strong influence of a single nucleotide ('T') at the cut site (position 17), though its impact on model predictions differed from the paper's biochemical interpretation.
- Questioned the reported importance of specific dinucleotides (e.g., TG, CG, GA), as their effects were not consistently supported across interpretability analyses.
- Concluded that the model relies more heavily on single-nucleotide features than originally proposed, offering a more nuanced and critical understanding of the model's decision-making process.